まずは、Windows 10 日本語版、JDK 10.0.2 でコマンドプロンプト上でビルド、生成された実行可能JARファイルを実行したところ文字化けが発生した。
C:\work\scenebuilder> gradlew -PVERSION=10.0.0 clean build
:
C:\work\scenebuilder\app\build\libs\scenebuilder-10.0.0-all.jar
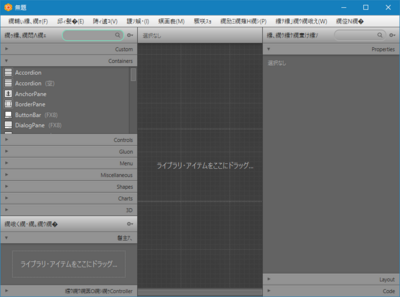
ビルドした実行可能JARファイルの中に含まれる日本語プロパティファイル(com/oracle/javafx/scenebuilder/app/i18n/SceneBuilderApp_ja.properties)の中身(メニューのファイルのプロパティを抜粋)
menu.title.file = \u7e5d\u8f14\u3043\u7e67\uff64\u7e5d\uff6b(F)
Gluonサイトで配布されている実行可能JARファイルの中に含まれる日本語プロパティファイルから同行抜粋
menu.title.file = \u30d5\u30a1\u30a4\u30eb(F)
ということで、文字化け発生している。JShellでそれぞれのユニコードエスケープ文字列を表示させてみると
jshell> System.out.println("\u30d5\u30a1\u30a4\u30eb(F)")
ファイル(F)
jshell> System.out.println("\u7e5d\u8f14\u3043\u7e67\uff64\u7e5d\uff6b(F)")
繝輔ぃ繧、繝ォ(F)
文字化けのパターンは、UTF-8の文字列をSJISとして解釈した場合に一致する。
再現方法の1つは、UTF-8で「ファイル(F)」と記述したファイルを作成し、コマンドプロンプト上でtypeで中身を表示させる。
C:\work> type file.txt
繝輔ぃ繧、繝ォ(F)
なお、ソースファイル上のプロパティファイルは、UTF-8で記述されている(ユニコードエスケープなし)。
Javaでは、java.io.FileReaderクラスを使ってデフォルトエンコーディング(Windows上であればSJIS系のWindows_31J)でUTF-8を読み込むと上述の様に化ける。
jshell> var reader = new BufferedReader(new FileReader("file.txt"))
reader ==> java.io.BufferedReader@13deb50e
jshell> System.out.println(reader.readLine())
繝輔ぃ繧、繝ォ(F)
{kind=link}